Created by Simon Karman
Published on 2021-03-21
Creating and maintaining application infrastructure in a cloud environment can be time consuming and a difficult process. A tool that allows us to deploy and update these resources from a parameterized template is a very powerful utility. Utilizing such a tool is commonly referred to Infrastructure as Code (IaC). A variety of awesome IaC tools exist for the Amazon Web Services (AWS) cloud. Most of these are focussed on writing configuration files, and are less focussed on writing actual source code in a programming language. In this article I would like to explain why I think writing your infrastructure as source code (IaSC) is a good idea and show that the AWS Cloud Development Kit (AWS CDK) is a great example of this.
Simon Karman
My name is Simon Karman. I am a professional Software Engineer and hobbyist Game Developer. I work at Tikkie (part of ABN AMRO Bank) via Quintor, where I am an AWS Cloud Engineer. My responsibilities include developing microservices in AWS, working on both serverless and containerized solutions. At Tikkie I have been using the Serverless Framework and AWS Cloud Development Kit (CDK) to successfully build and maintain 20+ microservices.
AWS
Amazon Web Services (AWS) is the cloud computing platform of Amazon. It enables companies and individuals to build and deploy applications in the cloud without needing to physically build and maintain their own data centers. This means that you can request a (virtual) machine in their data center and pay for it as long as you use it. You’ll generally install software on it, make sure your application is downloaded, and start your application. Recently serverless computing has taken this a step further. Instead of providing the developers with a running machine, they provide you with a running context for your application code. This means that you can write a function in your favorite programming language and define some rules on when that function should be invoked. In AWS creating such functions can be done in the service AWS Lambda. This is a very powerful instrument. One of the reasons for this, is that most of the AWS services (more than 100) can be used from, or can be used to invoke lambda functions. This makes AWS Lambda very versatile. An example of an AWS Lambda function: whenever a user makes an HTTP request on an AWS API Gateway that request is the trigger for your AWS Lambda to be invoked, the function can then return a response code (200) and a response body (some data).
Infrastructure as Code (IaC)
AWS provides developers with a console from which all the resources can be created, inspected, and altered. However, once you start working in a cloud environment it becomes apparent very quickly why you don’t want to do all of these operations by hand. For example: creating resources via an UI can be time consuming, you don’t want to click through some menu to create a simple database table everytime you need one. Moreover you’ll want some kind of version history and approval steps on changing your infrastructure. And lastly you’ll probably want to deploy your infrastructure multiple times, for example once to your test environment and once to your production environment. These three examples are hard to achieve with manual resource creation. To avoid such issues we’ll create our infrastructure from code. Infrastructure as Code (IaC) is the process of managing and provisioning computer data centers through definition files, rather than physical hardware configuration or interactive configuration tools.
AWS CloudFormation
The service of AWS that enables IaC is AWS CloudFormation. AWS CloudFormation allows you to write configuration files that describe the resources you want to create. A configuration file is called a CloudFormation template and it is written in JSON or YAML. These templates can contain parameters. You can deploy a template using AWS CloudFormation by providing the template and the parameters. AWS CloudFormation will automatically create all resources described in your template when you deploy it. You can reuse a template and provide different parameters each time. A template with its parameters and the associated resources are called an AWS CloudFormation Stack. Some resources in your template might require some additional data. For example when you use AWS Lambda functions in your template, you’ll also have to provide a zip file that contains the code of your functions. At some point you will also have to make changes to your infrastructure. You can simply update the template or change parameters of your stack. AWS CloudFormation will detect which resources in your infrastructure are affected by these changes and will figure out the best way to apply them.
We need a CloudFormation template (a yaml file) that contains all parameterized resources and a zip file (containing the source code) for the lambda functions.
AWS CloudFormation frameworks
Even though writing a CloudFormation Template has benefits over manual resource creation, it can still be quite challenging. You need to write YAML files that can grow to be multiple thousands of lines long and you will have to learn the specifics of the structure of CloudFormation templates. You’re essentially learning a new domain specific language (DSL) when you’re starting to learn CloudFormation. Luckily there are quite a few frameworks that help you write or generate CloudFormation templates. The two frameworks we will take a look at in this article are the Serverless Framework and the AWS Cloud Development Kit (AWS CDK).
The Serverless Framework allows you to very easily get started and make sure that everything around building a serverless service on top of AWS Lambda functions is very easy to create and build. Serverless essentially provides a shorthand notation for writing lambdas resources in CloudFormation. For all other resources that you want to define in your template you're on your own, and you will still need to write all that CloudFormation by hand.
Another great framework to highlight is Terraform. It can be used to generate a CloudFormation template by writing configuration files using the Terraform DSL. The upside is that Terraform is cloud platform agnostic, meaning that you can use it and everything you learn while working with it when working on cloud platforms other than AWS.
Configuration vs Source Code
Before we take at AWS CDK, let’s first take a closer look at the term ‘Infrastructure as Code’. Is the template used in the Serverless Framework (or Terraform) code? To answer this question let’s start with the definition of code: Code is information that instructs a computer which actions to execute. While these frameworks do adhere to the definition of code, as both Serverless and Terraform templates contain information that instructs AWS CloudFormation which resources to create or modify, they’re not the same as source code from a programming language. To make this distinction more clear, while still complying to the acronym IaC, I would like to propose to call these ‘Infrastructure as Configuration’ instead.
IaSC
Next thing you’re probably wondering is whether there are also tools in which you can write ‘Infrastructure as Source Code’ (IaSC)? What kind of benefits does IaSC give us over IaC?
A benefit of IaSC is that you’ll write code in a language you’re already familiar with, such as Java, TypeScript, Python, or Go. The important part is that this is not only a benefit for you as a developer, but also for the tools you’re working with, such as your integrated development environment (IDE). An IDE is already familiar with the type systems and data structures of those programming languages. This means that without needing to write a plugin or leaning fully on very specific documentation on how to use and access each part of the API of your framework, you can make use of the type systems of the programming languages.
A developer centric benefit is that learning a framework comes with a one time reward of knowing how to use that specific framework, while learning and using a general purpose programming language can benefit other parts of your development career too.
A very good example of a library that uses ‘Infrastructure as Source Code’ (IaSC) is the AWS Cloud Development Kit (AWS CDK).
Example Application
It can help to show the differences between IaC and IaSC by going through an example. I’ll explain the application we’re going to build and show how you could set it up with either the Serverless Framework or the AWS Cloud Development Kit (AWS CDK) using TypeScript.
The example application is a simple calculator. The calculator provides an HTTP endpoint (PUT /calculator) that allows you to execute an add or subtract operation on a counter in a database. The solution is built using AWS API Gateway for the REST endpoint, an AWS Lambda function to handle the invocation, and a DynamoDB table to store the counter details. The article focuses on the differences in how to set up the infrastructure and I will therefore NOT explain the functionality of the components used. You can read more about those in the documentation of AWS at https://aws.amazon.com/. The important thing to understand is that we need an API Gateway, a lambda function, and a DynamoDB table and that we’ll see how to create those resources in both frameworks.
Please note that although this example application focuses on Serverless resources, both frameworks can be used to develop containerized applications including resources such as EC2 instances, load balancers, and more.
All of the source code and configuration used for this example can be found on https://github.com/simonkarman/cdk-vs-serverless-framework.
Serverless Framework
Let’s first take a look at how to build the infrastructure behind the example project in the Serverless Framework. The Serverless Framework uses the serverless.yml file at its core. The serverless.yml file is actually very similar to a CloudFormation template. It has similar sections for resources, parameters, and more. However, it comes with some additional sections such as the functions and provider sections, which allow you to avoid a lot of boilerplate configuration that you would normally have to write when working with lambda functions directly in a CloudFormation template.
The serverless.yml file for our calculator application looks like this (for the full version visit the git repository):
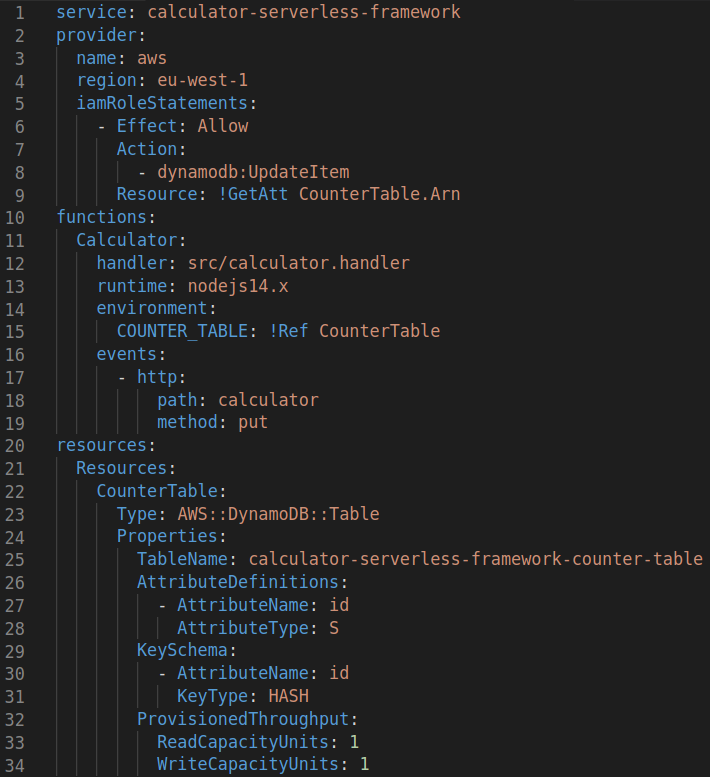
Let’s walk through the different sections. First up is the provider section. In the provider section we tell the Serverless Framework which cloud platform we use and to which region in that cloud platform we like to deploy. We can also use it to provide defaults that will be applied to all the functions we’ll define later. The iamRoleStatements is an array of statements that will be used to create the IAM role that the lambda functions will use. We ensure that we allow our function to update the entries in our database. Notice how we can easily reference it using !Ref followed by the name of the resource.
The second section is the functions section. For each function we define the Serverless Framework will create a Lambda function. We can provide which handler in our source code to invoke, which runtime to use, and provide environment variables that will be accessible during runtime to the function (using process.env.COUNTER_TABLE in this case). Lastly we specify in the ‘event’ section what kind of events this function should listen to. In this case we added an http event on the PUT method of the /calculator path. The serverless framework will automatically create an api gateway for us if any of our functions use the http event, as is the case in this example.
The last section is the resources section. In the resources section we’re all on our own again. The serverless framework allows you to write raw cloudformation in this section to add any other resources you need. In this case a dynamodb table. To know the structure of this section you’ll have to consult the AWS CloudFormation documentation. Here we create a AWS::DynamoDB::Table which we referenced in the lambda and iam role statement before.
The resulting CloudFormation template from these 34 lines of code is 389 lines long.
Benefits and Limitations
One of the benefits of the Serverless Framework is that it already knows how to package your source code into a zip file based on the chosen runtime. Building and bundling is therefore automatically done for you. Another benefit is that you don’t have to write a lot of the boilerplate configuration that’s needed when building microservices that have lambda functions at their core. This ensures that common functionality (such as an api gateway with lambda functions handling the requests) can be set up within a few minutes. Another benefit is that the functions section is similar when switching between different cloud providers.
One of the limitations of the Serverless Framework is that when you want to create resources outside the standard resources provided by the serverless framework, you’re on your own. In those cases you're still just writing plain CloudFormation. Another limitation is that apart from some basic yml checking, most of the typos and mistakes you make while developing your serverless yml only become noticeable during deployment. It's hard to tell from looking at the yaml file in your editor whether you’re using the right types for the right variables. Definitely in the resources section where you’re on your own. Another limitation is that it is hard to reuse structures in your infrastructure. You cannot resort to using a Cloud Formation feature called ‘nested stacks’, however the Serverless Framework itself does not provide you any help here. This limitation also means that it can be quite difficult to split up your service into multiple stacks as your projects grow. There are 3rd party plugins for the Serverless Framework that can help you here. And the last limitation is that you can not easily (unit) test your serverless yml file.
AWS CDK
Now it is time to build the same infrastructure using the AWS Cloud Development Kit (AWS CDK). Everything you build with AWS CDK is built out of individual building blocks called constructs. A construct can represent a single resource such as a DynamoDB table, or it can represent a higher level component consisting of multiple constructs. The key pattern behind this is composition, meaning that a construct can be composed from any number of lower-level constructs, and in turn, those could be composed from even lower-level constructs, which eventually are composed of AWS resources.
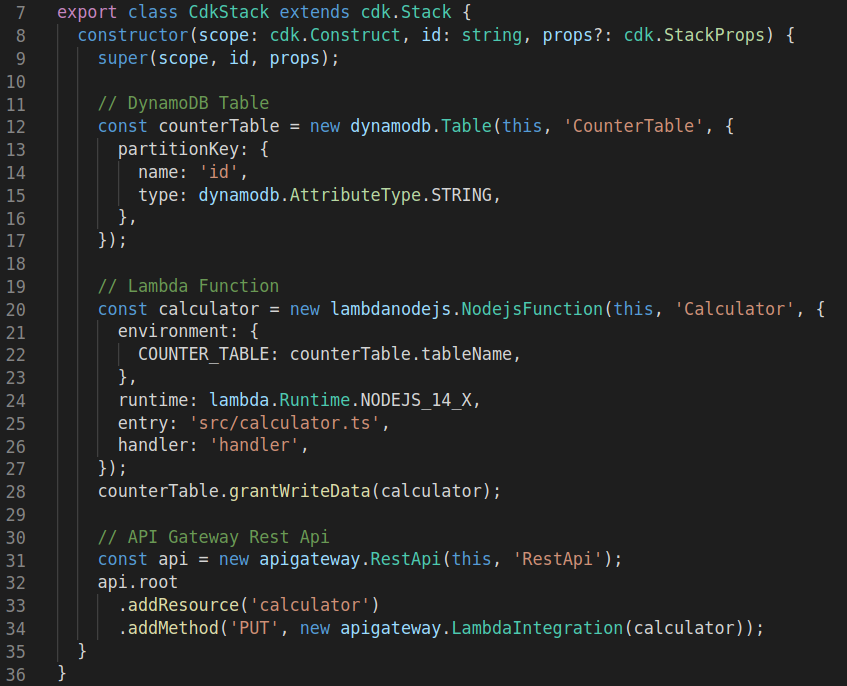
The cdk file for our calculator application looks like this (for the full version visit the git repository):
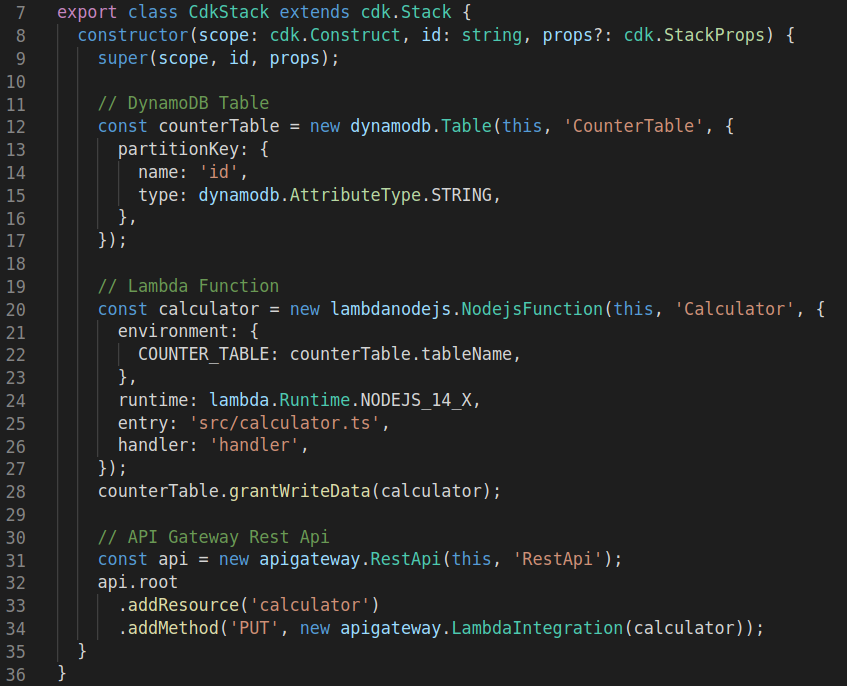
Let’s walk through the code. In CDK each construct has a constructor that follows the same pattern. The first argument is the scope. This is the construct to which you want to add the construct you’re creating. For our three resources this is always the stack itself, and therefore we use ‘this’. The second argument is the id of the resource. And the third parameter allows us to provide the options and properties for the construct.
First the DynamoDB table is created, since we’re using TypeScript the IDE will show a red line when you’re missing a required property, and also shows you the expected type of each property. For the attribute type of the dynamodb table we can use the provided enum from cdk for extra clarification.
To create the lambda function we need to specify the very similar properties as for the Serverless Framework. The environment, runtime, entry, and handler. Now that we have defined the dynamodb table and the lambda function we can use the grantWriteData method to ensure that our lambda function can write data to the dynamodb table. This line really shows the power of cdk, since we no longer need to write the role statements ourselves.
Lastly we create the rest api that will be used for the endpoint. We add the calculator resources, and on that add the PUT method, to which we assign the calculator lambda as the integration.
The resulting CloudFormation template from these 22 lines (line 12 to line 34) of code is 633 lines long.
Benefits and Limitations
One of the limitations of CDK is that it is fairly new. This means that some functionality which you might expect from a mature framework are still in experimental mode. One example of such an experimental feature is the NodeJSFunction that is used in the example, without it CDK doesn’t know how to package your code. There also exists a PythonJSFunction in experimental mode, however for the other programming languages these don’t exist. Another big limitation of CDK is the fact that it is only usable when working with AWS. It can not be used for other cloud providers. Another limitation is that the initial setup of an application requires a bit more setup than using a single configuration file. Another limitation is that you’re adding another layer of abstraction to the creation of your infrastructure. CDK still needs to be compatible with CloudFormation, thus still needing to coop with the limitation of CloudFormation itself. When you have zero experience with CloudFormation templates, some of the limitations can seem arbitrary or can be hard to understand from the context of CDK.
One of the benefits of CDK is that it is IaSC, thus you can build your application stack in your favorite programming language. This ensures that you’ll fail fast. If you’re using a typed language, and you’re using the wrong properties on an object, or mistyped on of the names, your code will simply not compile. This is especially powerful when working with resources you’re not familiar with, or when refactoring your infrastructure, this can really help you to identify problems quickly. Other intelligent features that IDEs and typed programming languages provide, such as deprecation warnings, which have been available for application source code for a long time, are available for your infrastructure too when using CDK, such features are very powerful.
The term ‘fail fast’ sounds negative. In general the earlier you fail the cheaper it is to fix. Therefore the faster you fail, the more early in development you’ll be able to fix the problems. The earlier you run into these failures the earlier you can fix them.
One of the greatest benefits is that CDK use composition. Composition is one of the fundamental concepts in object-oriented programming. It describes a class that references one or more objects of other classes in instance variables. This allows you to model a has-a association between objects. Composition in CDK makes it very easy to define reusable components and allows you to share them like any other code via a library. Composition is used in all layers of CDK, even in stacks. This means that by design a single CDK app can define multiple stacks. This ensures that CDK scales very well to larger applications.
Another great feature is the ability to unit tests your components. You can write unit tests for your construct that can test whether they result in the correct cloudformation based on the different parameters you provide to them.
CDK is available in multiple languages. CDK itself is written in TypeScript. To generate the library for these multiple languages, CDK uses the JSII framework. JSII can publish code written in TypeScript to a target language. More information on JSII can be found on https://github.com/aws/jsii.
Building a CDK library
Once you start building multiple microservices within an organisation you’ll start to notice that you’ll make certain choices and set up certain rules on how you want to build your infrastructure so that it is consistent across your landscape. CDK itself is not an opinionated framework, you create your resources in whatever way you want. However using the CDK library you can create your own component library to enforce certain standards. You're just writing source code, therefore you can publish a library using existing tooling. Simply publish the build artifacts to your artifact repositories in your company (or even publish them to a global repository if you think the rest of the world could also benefit from using your opinionated standards). If you stick to the same pattern as CDK does, and also use the JSII framework you can even ensure that your CDK construct library can be used in multiple programming languages.
When creating any library it is always a good idea to ensure that it doesn’t try to do too many things at once. It is important to determine what the use case of your library is.
The first reason that comes to mind is to give users of your library some interesting and commonly used functionality that can also be opt-out from. This part is opinionated, and as a developer you don't have to use it. For these common constructs the library should help, but not dictate.
The second reason that comes to mind is to ensure compliance of your resources according to the company's rules. If one of the company rules states that you should always create your s3 buckets with encryption enabled, you can create a custom construct that represents a s3 bucket that can only be created with encryption enabled. It enforces certain standards, properties, and security. For these common constructs the library should dictate, and you should be a conscious choice to be able to deviate from those standards.
I believe that it is best to split up these two different responsibilities in two separate cdk libraries. Each library has different goals and different timelines on which it might change. Having them separate ensures that you can independently publish and release them. Another benefit of this is that the compliance part could be a company wide library, while the common constructs can be team specific. Of course your common constructs part should be built on top of the compliance part.
Note that copying code is not always bad. Sometimes developers try to be too generic. While being able to make changes only local to your own copied version can also be a very flexible and fast way to work. Once a pattern emerges and it has reached a stable state and is being used in multiple places and you find yourself going through your projects to change the same thing in that logic to ensure consistency, that’s a good point to generalize and put into a library. I just can't stress enough: do not move code to your library or generalize your code too early.
An example of creating your custom resources is shown in the above code example. It adds some opinionated defaults such as the lambda runtime being nodejs14.x and a memory size of 1024mb, however these can be overwritten. It also enforces that a log retention of four months is used. This example is also part of the example https://github.com/simonkarman/cdk-vs-serverless-framework in the cdk/lib/karman-lambda-function.ts file.
Conclusion
We have seen how AWS enables developers to create infrastructure as configuration using the AWS CloudFormation service. Developers can do this by providing a YAML template file, however these files are cumbersome to write by hand. Frameworks exist that help developers to take shortcuts and to avoid writing a lot of boilerplate for your CloudFormation templates. Most of these frameworks still focus on writing your infrastructure as configuration (IaC) as opposed to writing your infrastructure as source code (IaSC). We have seen that there are benefits associated with IaSC such as being able to use existing tooling that is available for your programming language. We have seen that the AWS Cloud Development Kit (AWS CDK) is a great example of an IaSC framework by showing this in the context of an example application. And finally we have seen how AWS CDK can enable you to write a library with common constructs and compliancy standards for your infrastructure.